[RL-2] Hindsight Experience Replay#
Editor: 민예린 (Yerin Min)

1. Introduction#
강화학습은 바둑, 로봇 작업, 아타리 게임 등 순차적 의사 결정 문제를 풀기 위해 많이 사용됨
이러한 순차적인 의사 결정 문제를 잘 풀기 위해서는 보상 함수를 잘 정의하여야 하는데, 도메인 지식도 많이 필요하고 보상 함수 튜닝에도 시간이 많이 소요됨
아래 예시처럼 로봇으로 블록 쌓기 문제를 풀기 위해서는 (1) 블록을 잘 잡고 (2) 이동한 후 (3) 다른 블록 위에 쌓는 연속된 행동을 잘 해야 함
이때의 보상은 일반적으로 블록을 잡았을 때 +1, 내려 놨을 때 +1, 떨어뜨릴 때 -1 과 같이 정의될 수 있음
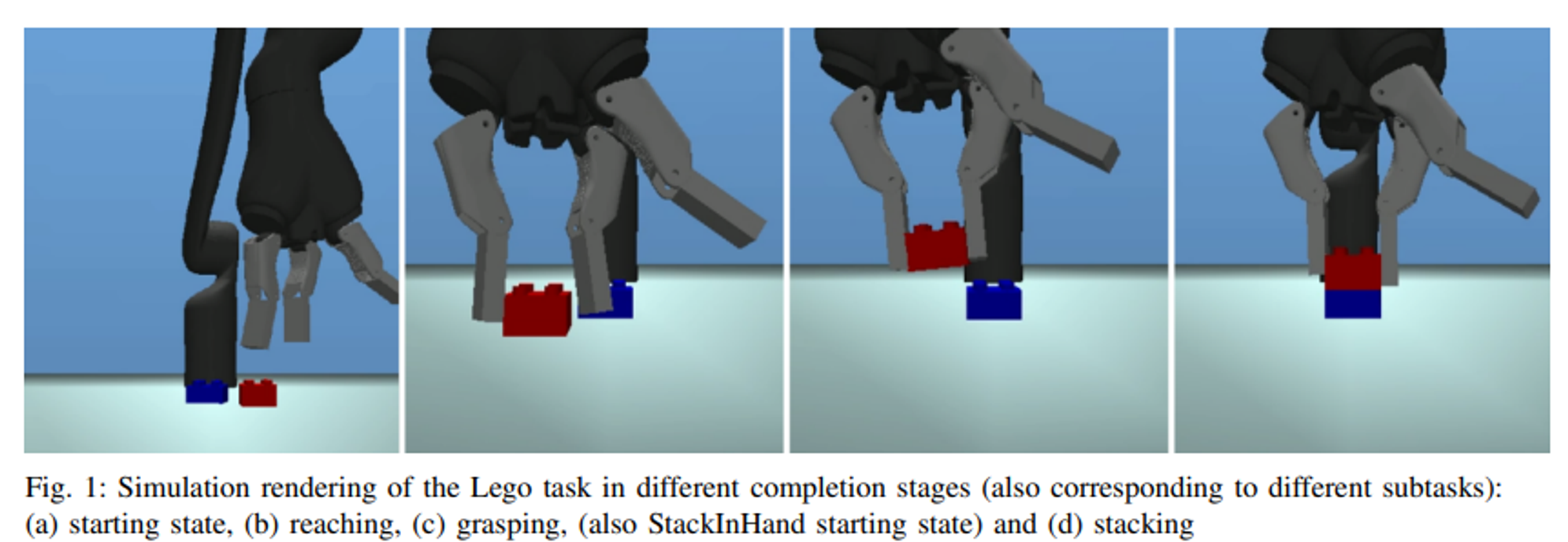
만약에 위와 같은 문제에서 빨간 블록을 잘 잡고 파란 블록 위에 놓았는데, 살짝 치우치게 놓아져서 자꾸 빨간 블록이 미끄러지는 상황이라고 가정해봤음
이때 +1 - 1 = 0으로 reward는 아무 것도 하지 않은 상황과 동일한 0이 되는 상황
로봇은 ‘살짝만 움직여서 내려 놓으면 된다’ 라는 사실을 0의 보상으로는 알 수 없게 됨
본 논문에서는 (1) 보상이 희소하거나 (2) 여러 목표를 달성해야 하는 경우 등 보상을 잘 정의하는 방법으로서 HER (Hindsight Experience Replay)를 소개하고 있음
2. Background#
On policy / Off-policy#
HER은 과거 기억을 활용해서 reward를 구성하는 방법이기 때문에 off-policy 알고리즘에 적용이 쉬운 방법임
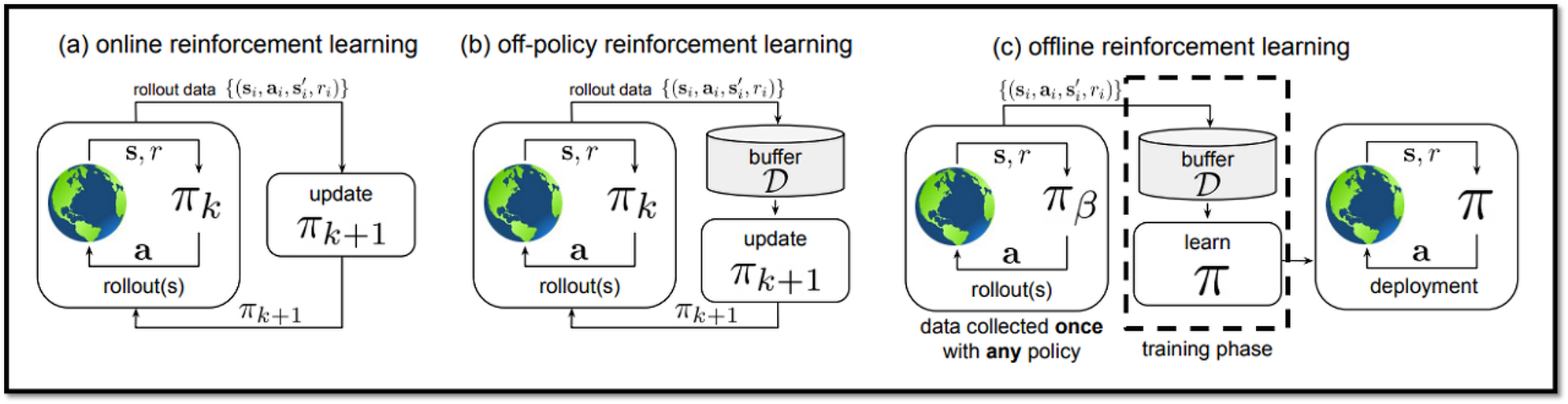
On-policy : 데이터를 수집하는 모델(behavior policy)과 학습하는 모델(target policy)가 동일
PPO, TRPO 등과 같은 알고리즘이 On-policy에 해당
Off-policy : 데이터를 수집하는 모델(behavior policy)과 학습하는 모델(target policy)가 동일하지 않음
DQN, DDPG 같은 알고리즘이 Off-policy에 해당
Universal Value Function Approximators (UVFA)#
UVFA는 여러 goal에 대해 학습할 수 있도록, value function을 정의한 방법론으로, HER에서 이와 같은 아이디어를 활용하고 있음
모든 goal \(g \in G\) 은 각각 고유 보상 값(\(r_g:S\times A \to \mathbb{R}\))들을 가지고 있음
모델의 입력으로는 state 뿐 아니라 현재 목표도 받게 되며, 따라서 value를 계산할 때도 goal 정보를 입력으로 받게 됨
\(\pi :S \times G\to A\)
\(Q^{\pi}(s_t,a_t,g)=\mathbb{E}[R_t|s_t,a_t,g]\)
3. Hindsight Experience Replay#
기본 아이디어#
💡 실패한 경험도 돌아보면서, 재활용할 경험이 있는지 보자!
예를 들어, reward가 \(r_g(s,a) =-||s-g||^2\)와 같이 정의되어 있는 환경이라고 해봄
T 시점에서 목표 g를 실패했을 때, g를 \(s_T\)로 바꾸면 \(s_T\)를 달성하는 방법에 대해 배울 수 있음
이렇게 하면 실패한 경험도 재활용할 수 있기 때문에 효율적으로 다양한 목표들에 배울 수 있다고 함

알고리즘#
하지만 모든 문제들이 state와 goal을 동일하게 정의할 수 있는 것은 아니고, 특히 앞서 intro.에서 설명한 것 같이 다양한 goal을 가지는 문제의 경우 단순하게 g → \(s_T\)로 바꾸는 방법을 사용할 수는 없음
HER은 replay buffer에 원래 목표뿐만 아니라, additional goals을 sampling 해서 goal로 활용한다고 함

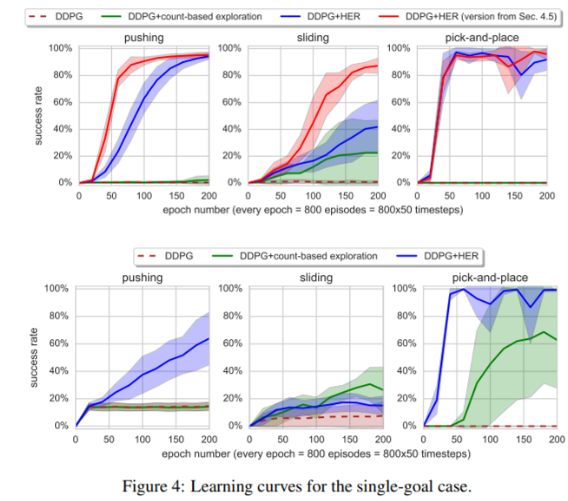
4. Experiment#
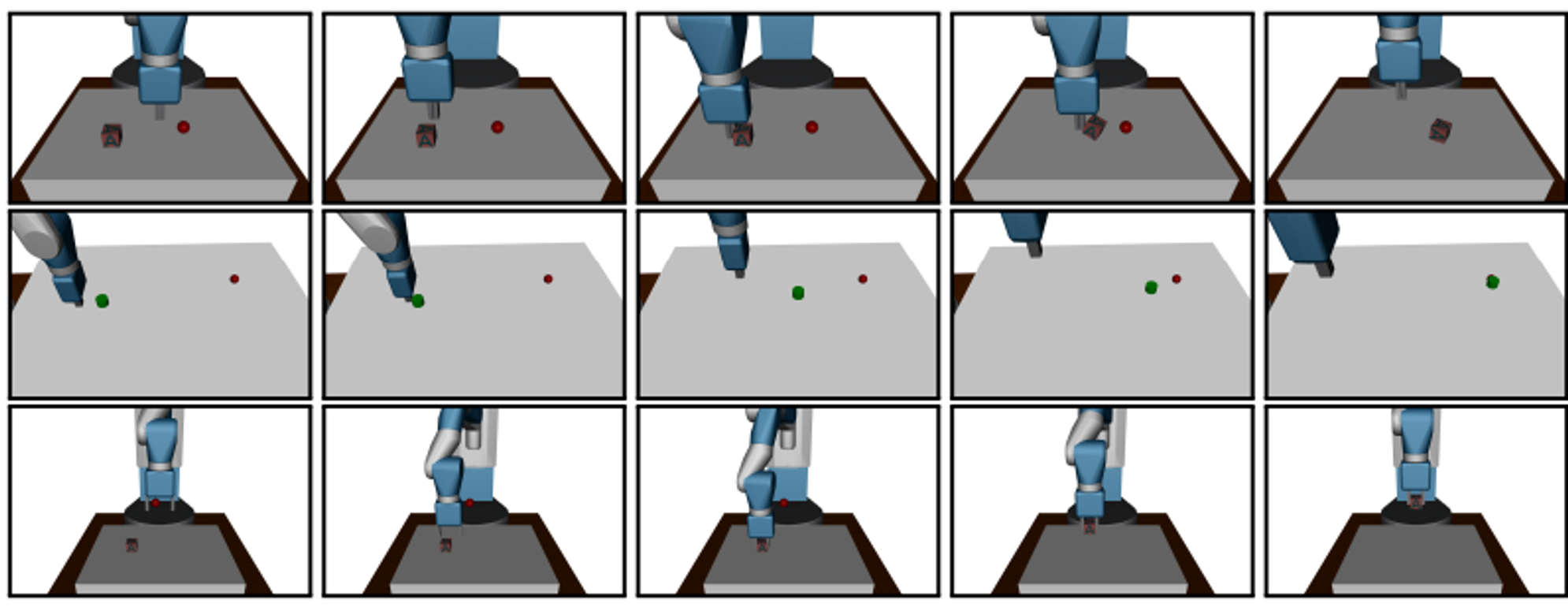
문제 정의 : object를 target location (빨간 점) 으로 옮기기
이를 위해 pushing, sliding, pick and place task 존재
State : robot joints의 velocities, angles, positions, rotations 등
Goals : object의 position
action :
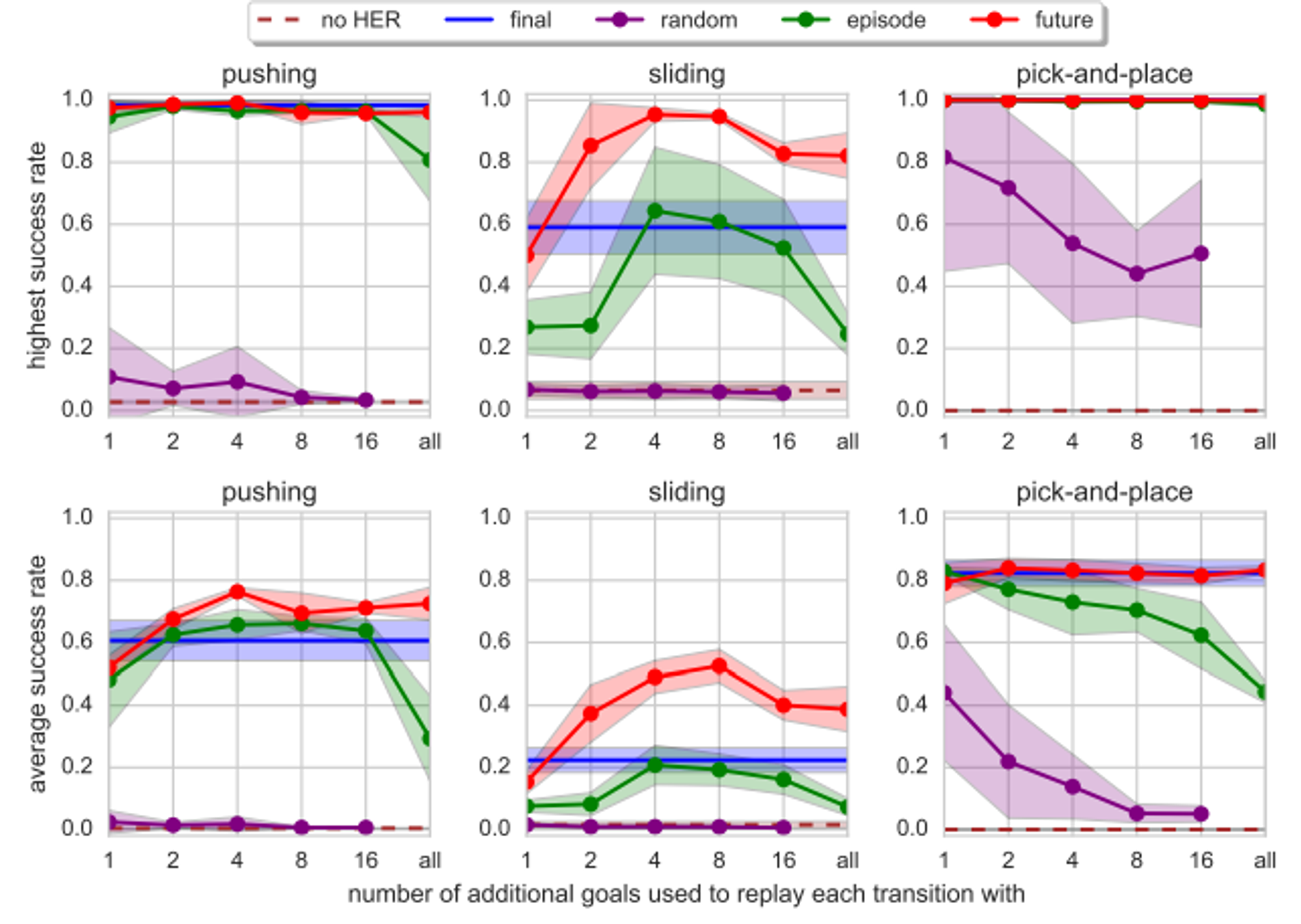
multi-goal & singe goal setting 일 때 성능
샘플링 방법과 샘플 수에 따른 성능 비교 : Future가 가장 성능이 좋음
final : goal을 해당 trajectory 내 마지막 state로 재평가
future : 선택한 trajectory 내에서 선택된 sampled state를 기준으로, 임의의 step time 이후 도달하는 state를 goal로 활용
episode : 선택한 trajectory 내에서 선택된 sampled state의 위치와 상관없이 trajectory 내부 임의 state를 goal로 활용
random : trajectory와 관계없이 학습 중 경험한 전체 state 중 임의의 state를 goal로 활용 -> 이 부분은 논문으로는 정확하게 이해가 안 가서 블로그 참고함 (https://ropiens.tistory.com/136)